3月19日消息,今晚刷微博,突然发现有朋友再说淘宝旺旺服务器可能瘫痪了,因为卖家集体高冷,什么问题都不回答了。直接上图
来说说旺旺服务器吧,大家可能不大清楚,毕竟在我们看来双十一这样的电商节淘宝都没事现在就出事了?

淘宝海量数据产品技术架构
数据产品的一个最大特点是数据的非实时写入,正因为如此,我们可以认为,在一定的时间段内,整个系统的数据是只读的。这为我们设计缓存奠定了非常重要的基础。
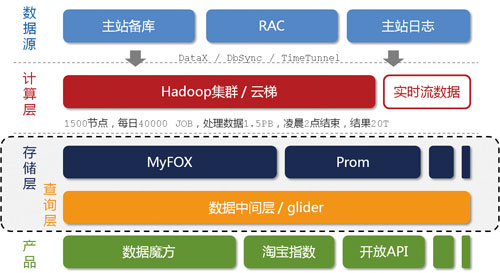
图1 淘宝海量数据产品技术架构
按照数据的流向来划分,我们把淘宝数据产品的技术架构分为五层(如图1所示),分别是数据源、计算层、存储层、查询层和产品层。位于架构顶端的是我们的数据来源层,这里有淘宝主站的用户、店铺、商品和交易等数据库,还有用户的浏览、搜索等行为日志等。这一系列的数据是数据产品最原始的生命力所在。
在数据源层实时产生的数据,通过淘宝自主研发的数据传输组件DataX、DbSync和Timetunnel准实时地传输到一个有1500个节点的Hadoop集群上,这个集群我们称之为“云梯”,是计算层的主要组成部分。在“云梯”上,我们每天有大约40000个作业对1.5PB的原始数据按照产品需求进行不同的MapReduce计算。这一计算过程通常都能在凌晨两点之前完成。相对于前端产品看到的数据,这里的计算结果很可能是一个处于中间状态的结果,这往往是在数据冗余与前端计算之间做了适当平衡的结果。
不得不提的是,一些对实效性要求很高的数据,例如针对搜索词的统计数据,我们希望能尽快推送到数据产品前端。这种需求再采用“云梯”来计算效率将是比较低的,为此我们做了流式数据的实时计算平台,称之为“银河”。“银河”也是一个分布式系统,它接收来自TimeTunnel的实时消息,在内存中做实时计算,并把计算结果在尽可能短的时间内刷新到NoSQL存储设备中,供前端产品调用。
容易理解,“云梯”或者“银河”并不适合直接向产品提供实时的数据查询服务。这是因为,对于“云梯”来说,它的定位只是做离线计算的,无法支持较高的性能和并发需求;而对于“银河”而言,尽管所有的代码都掌握在我们手中,但要完整地将数据接收、实时计算、存储和查询等功能集成在一个分布式系统中,避免不了分层,最终仍然落到了目前的架构上。
为此,我们针对前端产品设计了专门的存储层。在这一层,我们有基于MySQL的分布式关系型数据库集群MyFOX和基于HBase的NoSQL存储集群Prom,在后面的文字中,我将重点介绍这两个集群的实现原理。除此之外,其他第三方的模块也被我们纳入存储层的范畴。
存储层异构模块的增多,对前端产品的使用带来了挑战。为此,我们设计了通用的数据中间层——glider——来屏蔽这个影响。glider以HTTP协议对外提供restful方式的接口。数据产品可以通过一个唯一的URL获取到它想要的数据。以上是淘宝海量数据产品在技术架构方面的一个概括性的介绍。
淘宝数据产品选择MySQL的MyISAM引擎作为底层的数据存储引擎。在此基础上,为了应对海量数据,我们设计了分布式MySQL集群的查询代理层——MyFOX,使得分区对前端应用透明。
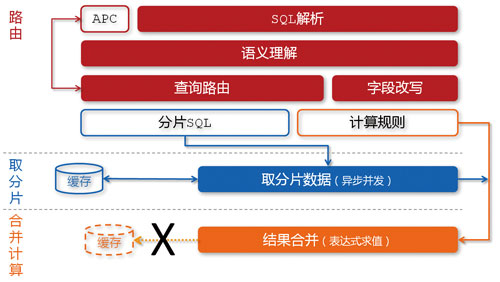
图 MyFOX的数据查询过程
目前,存储在MyFOX中的统计结果数据已经达到10TB,占据着数据魔方总数据量的95%以上,并且正在以每天超过6亿的增量增长着。这些数据被我们近似均匀地分布到20个MySQL节点上,在查询时,经由MyFOX透明地对外服务。
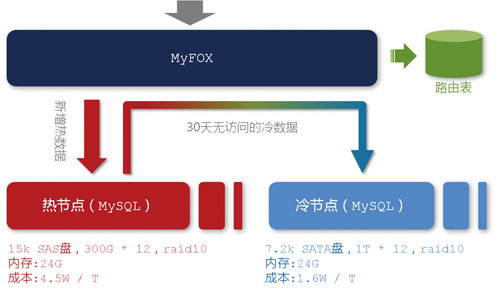
图 MyFOX节点结构
值得一提的是,在MyFOX现有的20个节点中,并不是所有节点都是“平等”的。一般而言,数据产品的用户更多地只关心“最近几天”的数据,越早的数据,越容易被冷落。为此,出于硬件成本考虑,我们在这20个节点中分出了“热节点”和“冷节点”(如图4所示)。
顾名思义,“热节点”存放最新的、被访问频率较高的数据。对于这部分数据,我们希望能给用户提供尽可能快的查询速度,所以在硬盘方面,我们选择了每分钟15000转的SAS硬盘,按照一个节点两台机器来计算,单位数据的存储成本约为4.5W/TB。相对应地,“冷数据”我们选择了每分钟7500转的SATA硬盘,单碟上能够存放更多的数据,存储成本约为1.6W/TB。
将冷热数据进行分离的另外一个好处是可以有效提高内存磁盘比。从图4可以看出,“热节点”上单机只有24GB内存,而磁盘装满大约有1.8TB(300 * 12 * 0.5 / 1024),内存磁盘比约为4:300,远远低于MySQL服务器的一个合理值。内存磁盘比过低导致的后果是,总有一天,即使所有内存用完也存不下数据的索引了——这个时候,大量的查询请求都需要从磁盘中读取索引,效率大打折扣。
只能说,淘宝服务器出问题可能是数据库问题也可能是解析。具体问题等阿里出公告吧。
