Meta不仅是全球最大的社交网络公司,和当下最热门技术概念“元宇宙”的推行者。它同时也是人工智能(AI)研究的全球顶级公司之一。该公司在AI方面卓越研究成果的背后,必然有强大的算力支持。不过一直以来,Facebook从未对外界公开展示过其算力究竟有多厉害。
为元宇宙加码!Meta推出全球最快AI超级计算机
文/杜晨
而在今天,Meta公司突然对外宣布了其在打造AI超级计算机方面的最新进展。
根据Meta此次公开透露的结果,其打造的超级计算机AIRSC,目前算力在全球应该已经排到了前四的水平。
这个情况已经足以令人非常震惊。毕竟,在算力方面能够和RSC相提并论的其它超级计算机,均由中国、美国、日本的国有研究机构运作——而RSC是前五里唯来自于私营机构的超算系统。
这还没完:这台超级计算机,还在以惊人的速度,变得更快、更强。
Meta预测,到今年7月,也即半年之内,RSC的算力将实现2.5倍的增长。另据专业机构 HPCwire估计,Meta的RSC超级计算机,其运行 Linpack benchmark 的算力将有望达到220 PFlops。
如无意外,RSC将成为名副其实的“全球最快AI超级计算机”。

AIRSC内部,图片来源:Meta
AI研发进入“超算”时代
首先需要回答一个问题:
什么样的AI研究,需要如此强大的超级计算机?
一般的模型,或许可以在一般的电脑或普通的数据中心里,用一块或是几块显卡就可以完成训练。而Meta正在研究的,是比目前的模型参数量要大得多,性能要求更高、更严格,训练花费时间更久的——超大模型。
以识别有害内容为例:CV算法需要能够以更高的采样率,处理更大、更长的视频;语音识别算法需要在极大噪音的复杂背景下达到更高的识别准确度;NLP模型要能够同时理解多种语言、方言和口音,等等……
在过去,许多算法在跑分数据集上都得到了不错的成绩。然而,Meta是一家几大洲十亿级别用户量的公司,它必须确保同一个模型投放到生产环境中能够最大限度保证普适性。所以,一般模型不够用了,现在要训练大模型。
训练大模型,需要大算力——问任何一个从事大模型研究的人,你都会得到这样的答案。毕竟过去的训练任务用几周能够完成,可在今后,面对新的大模型,我们可等不起几年……
“在今天,包括识别有害内容等在内的许多重要的工作,都对于超大模型产生了极大的需要,”Meta在其新闻稿中写道,“而高性能计算系统是训练这些超大模型的重要组件。”
Meta此次发布的超级计算机AIRSC,全称为AIResearchSuperCluster(人工智能研究超级计算集群)。
虽然Meta在今天首次公开宣布推出这一系统,实际上RSC的前身版本最早在2017年就已经在Facebook公司内部投入生产使用了。当时,Facebook团队采用了2.2万张英伟达V100TensorGPU组成了首个单一集群。该系统每天可以运行大约3.5万个训练任务。
据HPCwire预计,这个基于V100GPU的前身版本,按照Linpack benchmark的浮点计算性能应该已经达到了135PFlops。这个水平在全球超算排行榜Top500的2021年11月排名中,已经足以排到第三名了,也即其算力可能已经超越了美国能源部在加州Livermore运作的“山脊”(Sierra)超级计算机。
不过,对于Meta来说,这还远远不够。他们想要的,是世界上最大、最快、最强的AI超级计算机。
这台超算还必须要达到生产环境的数据安全级别,毕竟在未来,Meta的生产系统所用的模型可能直接在它上面训练甚至运行。
并且,这台超算还需要为用户——Meta公司的AI研究员——提供不亚于一般训练机/显卡的使用便利性,和流畅的开发者体验。

MetaAIRSC技术项目经理KevinLee 图片来源:Meta
2020年初,Facebook团队认为当时公司的超算集群难以跟上未来大模型训练的需要,决定“重新出发”,采用最顶尖的GPU和数据传输网络技术,打造一个全新的集群。
这台新的超算,必须能够在大小以EB(超过10亿GB)为单位的数据集上,训练具有超过万亿参数量的超大神经网络模型。
(例如,中国科研机构智源BAAI开发的“悟道”,以及Google去年用SwitchTransformer技术训练的混合专家系统模型,都是参数量达到万亿级别的大模型;相比来看,此前在业界非常著名的OpenAIGPT-3语言模型,性能和泛用性已经非常令人惊讶,参数量为1750亿左右。)
Meta团队选择了三家在AI计算和数据中心组件方面最知名的公司:英伟达、PenguinComputing,和PureStorage。
具体来说,Meta直接从英伟达采购了760台DGX通用训练系统。这些系统包含共计6080块Ampere架构TeslaA100Tensor核心GPU,在当时,乃至今天,都是最顶级的AI训练、推理、分析三合一系统。中间的网络通信则采用了英伟达InfiniBand,数据传输速度高达200GB每秒。
存储方面,Meta从PureStorage采购了共计231PB的闪存阵列、模块和缓存容量;而所有的机架搭建、设备安装和数据中心的后续管理工作,则由从Facebook时代就在服务该公司的PenguinComputing负责。
这样组建出来的新超算集群,Meta将其正式命名为AIRSC:
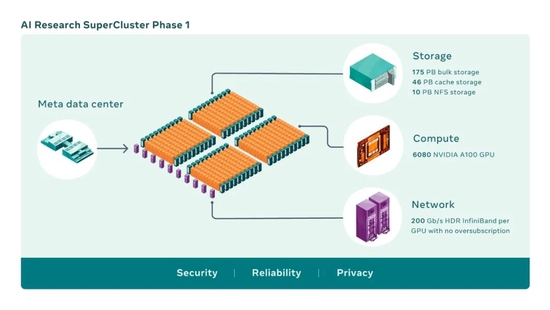
图中显示的是RSC第一阶段(P1)的参数细节。图片来源:Meta
相较于之前FAIR采用V100 显卡搭建的计算集群,初代 RSC对于生产级别的计算机视觉类算法带来了20倍的性能提升,运行英伟达多卡通讯框架的速度提升了超过9倍,对于大规模自然语言处理类 workflow 的训练速度也提升了3倍——节约的训练时间以周为单位。
值得一提的是,在Meta刚刚做好RSC升级计划的时候,新冠疫情突然袭来了。所有实体建造的工期都遇到了极大的不确定性,RSC能否成功升级换代,打上了一个巨大的问号。
然而,公司业务发展和AI科研的需要,无法等待新冠疫情。负责RSC升级和建造的团队,以及包括英伟达、PenguinComputing、PureStorage等三家硅谷公司在内的技术合作方,不得不在极大的工期压力下,完成数据中心的装修建设、设备的生产和运输、现场装机、布线、调试等一系列非常繁琐和技术要求极高的工作。
更夸张的是由于当时全美各地都有居家隔离令,整个RSC项目团队的多位负责人,都不得不在家中远程工作……团队里的研究员ShubhoSengupta表示,“最让我感到骄傲的是,我们在完全远程办公的条件下完成了(RSC的升级工作)。考虑到项目的复杂性,完全没有和其它团队成员见面就能把这些事都办了,简直太疯狂了”

就目前来看,RSC已经是世界上运行速度最快的AI超级计算机之一了。
但是Meta仍不满足。
打造全球最快、最安全的AI超算
为了满足Meta在生产环境和AI研究这两大方面日益增长的算力需求,RSC必须持续升级扩容。
按照Meta的RSC第二阶段(P2)计划,到今年7月,也即半年之内,整个计算集群的A100GPU总数提升到惊人的1.6万块……
初代RSC采用的DGXA100单机数量是760台,折合6,080张显卡——这样计算的话,也就是说RSC将在P2 再增加9,920张显卡,即Meta需要再从英伟达采购1,240台DGXA100超级计算机……
就连英伟达也表示,Meta的计划,将让RSC成为英伟达DGXA100 截至目前最大的客户部署集群,没有之一。

算力提升了,其它配套设施,包括存储和网络,也要跟上。
按照Meta的预计,RSC 的P2完成后,其数据存储总量将达到1EB——折合超过10亿GB。
不仅如此,整个超算集群的单个节点之间的通讯带宽也获得了史无前例般的提升,达到惊人的16TB/s,并且实现一比一过载(也即每个DGXA100计算节点对应一个网络接口,不出现多节点共享接口争抢带宽资源的情况)
(这里还有个点值得单独提一下:按照Meta团队的估计,像RSC这样采用DGXA100节点组建超算集群的做法,能够支持的节点上限也就是1.6万了,再多就会出现过载,意味着追加投资的边际收益显著降低。)


在数据安全的角度,Meta这次也没有忘了在新闻稿中专门介绍其数据处理方式,以求令公众安心。
“无论是检测有害内容,还是创造新的增强现实体验——为了打造新的AI模型,我们都会用到来自公司生产系统,取自真实世界的数据,”Meta表示,这也是为什么RSC从设计之初就加入了数据隐私和数据安全方面的考虑。只有这样,Meta的研究院才能够安全地使用加密、匿名化后的真实世界数据来训练模型。
1)RSC被设计为无法和真正的互联网直接连接,而是和位于RSC所在地附近的一座Meta数据中心进行连接;
2)当Meta的研究人员向RSC的服务器导入数据的时候,这些数据首先要通过一道隐私审查系统,确认数据已经进行了匿名化;
3)在数据正式投入到AI模型算法的训练之前,数据也会再次进行加密,并且密钥是周期生成和抛弃的,这样即使有旧的训练数据存储,也无法被访问;
4)数据只会在训练系统的内存中解密,这样即使有不速之客闯入RSC,对服务器进行物理访问,也无法破解数据。
可能是出于保密的目的,Meta甚至连 RSC的具体所在地都没有透露……
不过根据已知的情况,RSC的附近必有一座Facebook/Meta数据中心存在。并且,下图截取自RSC的公告视频,图中我们可以看到,AIRSC位于右上,左下则是Meta的一座数据中心。图中有着大量较高的树木。

硅星人基本可以确定,上图中的Meta数据中心位于美国弗吉尼亚州Henrico县。该县是美国东部最大的数据中心集中地,也是连接欧洲、南美、亚洲、非洲的多条海底光缆在美国的末端所在地。至于RSC的实际所在地,其前身应该是QTSRichmond数据中心。
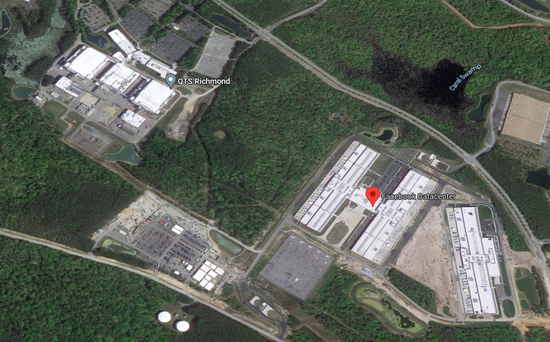
右边为Meta数据中心,左边为QTSRichmond也即MetaAIRSC所在地 截自GoogleMaps
最后,让我们来看看成本……
不考虑同样极其昂贵的存储和网络基础设施,我们就先只看计算的部分:
每台DGXA100的标准售价为19.9万美元,Meta大宗采购肯定有折扣,但假设没有折扣的话:RSC这次P2的扩容成本,仅显卡采购的部分,就高达2.5亿美元……)
当然,按照今天的Meta市值来看,这笔费用简直是九牛一毛。假若真的打造出全世界最大最强最快的AI超算,对于这家公司的业务,无论是其现在的核心业务,还是未来的元宇宙产品,预计都能够带来非常大的帮助。
Meta是这么说的:“最终,我们在RSC上面的努力,将能够为作为下一个关键计算平台的元宇宙铺就道路。届时,AI驱动的应用和产品将会扮演重要的角色。”