
2023年的WAVE SUMMIT深度学习开发者大会来得比往年稍晚了些,却有着不同寻常的意义。
过去半年多时间里,大模型可以说是驻留在浪尖的一个名词。几乎所有行业都在讨论大模型的话题,涌现了哪些超出预期的能力,将对产业产生什么样的影响,以及大模型浪潮下的机会窗口在哪里。
诚如百度CTO王海峰在主题演讲中的观点:以大语言模型为代表的人工智能正在深入千行百业,加速产业升级和经济增长。在这个进程中,技术创新和应用落地形成良性循环,理解、生成、逻辑、记忆等能力持续提升,产业应用的广度和深度持续拓展,大语言模型为通用人工智能带来曙光。
而对于大模型所能释放出的生产力,百度集团副总裁、百度首席信息官李莹也在演讲中进行了系统的阐述,并以百度旗下的智能工作平台如流为例,深度拆解了大模型如何重构办公场景新范式。
01 两个“智能浓度”极高的黑科技
时间回到四个月前,“文心一言在百度内部全面应用在智能工作平台如流”的消息吸引了许多人的注意。外界还在讨论怎么获取文心一言的邀请码时,如流已经在文心大模型的加持下实现了智能创作、编码智能推荐等功能,并在百度内广泛使用。
个中原因并不难解释。
协同办公是天然的高知识密度场景,每天有大量的文档、消息、记录等知识沉淀;大模型恰恰擅长推理、归纳和创造,最早被发掘的正是图像、写作等知识型的技能。大模型和协同办公的相遇,可以说是百度内部对大模型提升工作生产力能力的直接验证,想要掀起一场一拍即合的效率革命。
2023 WAVE SUMMIT的主论坛上,百度集团副总裁、百度集团首席信息官李莹在演讲中特意演示了如流的两个“黑科技”。
第一个是超级助理。
借用李莹的原话,超级助理可以理解为一个人人拥有的,懂你、专业、实时陪伴的工作助理。基于用自然语言输入的需求,超级助理可以通过调用插件完成文档处理、会议预定、差旅安排、数据分析等任务,将原本小时级的工作内容,被压缩到了分钟级乃至秒级。
比如语音输入“我后天上午去上海研发中心开会,当天返回北京,请帮我规划行程”的指令后,超级助理会先查询用户的日程,发现明天上午有会议时,温馨地预订了下午的机票,并且人性化地推送了百度上海研发中心附近酒店。
再比如需要做BI分析时,可以用自然语言问超级助理“最近的销售目标完成情况如何”,会自动查询相关销售数据,并生成表格、柱状图等分析结论,甚至可以评估销售目标的风险、查询最近的商机、分配各团队的工作。
第二个是Comate X智能编程助手。
早在去年9月份,百度就已经基于文心大模型开发了智能研发工具Comate,而后基于“文心一言”的新能力,升级成为Comate X智能编程助手,可实现代码的快速补齐、自然语言推荐代码、自动查找代码错误以及注释的生成、接口的生成等等,目前已经支持30多种语言、10多种IDE。
在现场的演示中,百度的工程师向Comate X输送写一个激活码程序的任务后,几分钟内即实现了代码生成、代码注释、单元测试等一系列操作,工程师在整个过程中没有操作一行代码。
两个“黑科技”放在大会最后产业实践篇,但不难从中看到极高的“智能浓度”。
不管是超级助理还是Comate X,都在某个场景下提供了全链条服务,用户只需要准确描述需求,在执行任务的过程中不需要或者仅需人类简单的确认操作,至于如何理解需求、如何整合系统、如何生成答复,都由AI自动去完成,很多冗长的过程被大模型的能力给“折叠”了。
02 回到问题起点的AI原生思维
其实在生成式AI走红后,不少产品开始了智能化改造,譬如将大模型能力和语音识别融合,用于增强会议速记的准确性;将写作能力移植到笔记类产品,试图帮助用户根据大纲自动生成内容…….
可从实际体验来看,很多都属于“半拉子”产品,只承担单一功能、解决碎片问题。对此,李莹的观点非常鲜明:“生成式AI革命带来的不仅仅是一种可以嵌入到产品里的技术元素,更是一种新的基于AI原生的思维方式。”
在企业办公领域,对于什么是AI原生思维,李莹曾在媒体采访中用“Native Language(原生语言)”做过类比:母语就是原生语言的代表,我们一切思维的起点都是通过母语逻辑进行思考,表达自然而然发生;同样,AI原生思维需要回到问题的的起点,用AI的视角来思考、用AI的框架来分析、用AI的方式来解决。
直接的例子就是如流的超级助理。

在策划“超级助理”这个产品时,如流内部确定了三个产品特征。首先是“懂你”,通过持续学习员工的习惯、偏好、工作模式,能够实时地了解员工的需求;然后是“专业”, 不仅有广泛的通识知识,还要具有细分领域和企业的私域知识,并能做专业的任务执行;接下来是“实时陪伴”, 随时随处都可以唤起,并可以在适时的时候跟用户进行主动的交互、通知、提醒等等。
想要实现这样的能力,绝非是将AI整合进某个模块就能解决的,确切地说,如流为此重塑了两个流程:
一是重塑工作流程。传统的办公流程通常要安装IM、OA、CRM等多个产品,然后在多个系统、应用间来回切换。超级助理提供的是一个入口,用户通过自然语言交互的方式,获取不同系统的功能。对于用户来说,只需要在这个向超级助理描述需求,不需要关心背后的系统是什么。
二是重塑IT系统框架。传统的IT系统多半是独立的,数据互不连通,想要用统一入口去交互,前提是每一个系统的能力被原子化、插件化,就像差旅系统的预订能力、日程设置能力,先成为大模型的插件,将系统改造成是对模型友好的,然后被超级助理用来满足用户的需求。
再来理解李莹眼中的AI原生思维,核心就是要跳出产品开发的固有范式,回到问题的起点,深入思考用户的需求是什么,再用AI端到端去解决,无形中改写了用户和需求之间的关系,对传统场景进行了重构。
做一个总结的话,如流基于AI原生思维打造的超级助理,不再局限于对话式的问答,对用户的工作内容、协作情景、角色信息等进行深入理解,小到一个知识点,大到复杂的流程审批,都能直接满足。
03 “创新流水线2.0”,加速知识循环
按照百度创始人、CEO李彦宏的说法:“大模型时代来了,每一个产品都值得重做一遍。”用AI原生思维重构的如流,所瞄准的不只是效率的提升,同时也在赋能企业的知识管理。
对知识管理稍有了解就会知道,这并不是一件容易的事。比如很多企业想要把知识沉淀下来,然而,收集与记录只是知识管理的起点,知识要释放出价值,还需要整理、输出与循环。一个司空见惯的现象,员工离职时往往会交接一份长长的文档,但文档并不能和知识划等号,人离职的时候,知识也就流失了。
李莹在2022年提出了“创新流水线=AI×知识管理”的理念,希望用AI的能力重塑整个知识管理的过程,即先用大模型学习异构知识,再利用搜索和推荐的能力去分发,继而帮助员工更好地应用知识,形成创新的正循环。
这样的一套逻辑相当有想象力,假如知识可以不断地循环流动起来,意味着每一个员工都可以站在“巨人的肩膀上”做创造性的工作。其中的挑战在于,能否将沉淀的资料形成有用的知识,能否让员工简单高效地获取知识,能否在知识管理的基础上辅助创新。
当大模型时代来临,创新流水线该怎么做?
和许多新物种的诞生相似,大模型也在经历蒙眼狂奔的局面,以至于有人用“百模大战”来形容这一盛况。所幸在鱼龙混杂的大模型江湖里,并不缺少一些权威机构和媒体的评测,客观还原了大模型的真实现状。
IDC发布的《AI大模型技术能力评估报告》显示,百度文心大模型在14个参评模型中拿下12项指标的7个满分,综合评分位列国内主流大模型第一;人民数据发布的《AI大模型综合能力测评报告》显示,文心一言不仅综合评分超越ChatGPT,位居全球第一……
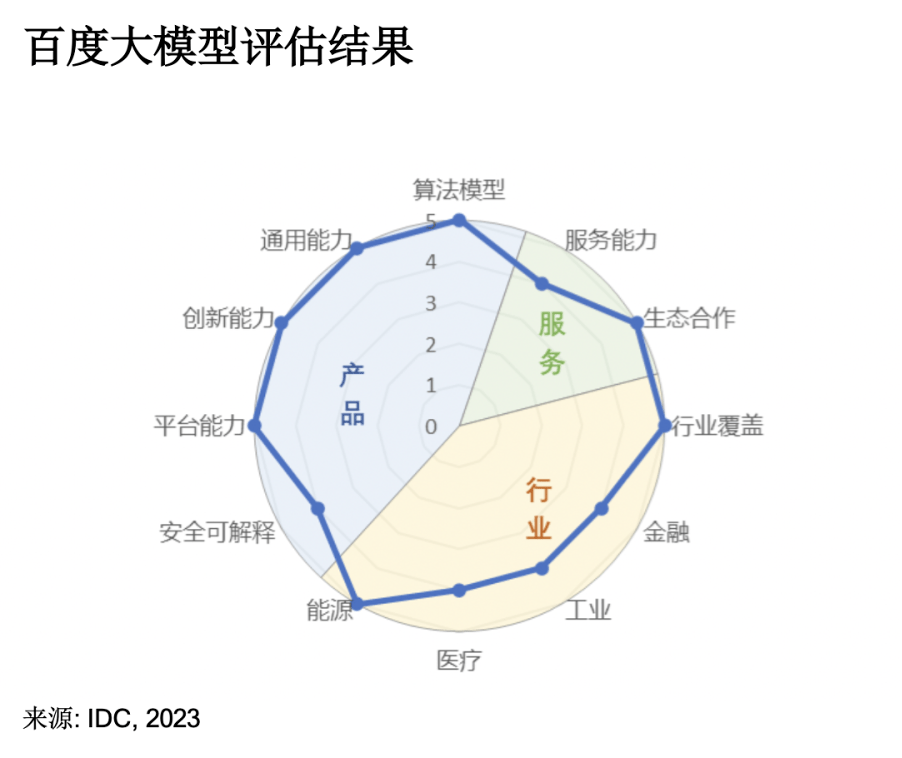
基于文心大模型全方位技术积淀,李莹在WAVE SUMMIT上提出升级知识管理理念至“创新流水线2.0”,大模型带动创新流水线核心引擎升级,随之而来的是技术底座、知识管理对象、知识管理运行方式和产品形态四大方面全面升级。大模型可以不断学习相关的企业知识,将知识范畴从文本和数据延伸到了系统及服务能力,并在知识理解生成的同时,拥有很强的执行能力,去完成工作任务。
前面提到的超级助理,就是“创新流水线2.0”理念下的AI原生应用。除了预定会议、群聊转发、跨端学习等能力,超级助理的应用场景还包括智能文档处理,以“查文档”为例,即使忘记了文档名称,只要向超级助手描述需求或文档出现场景,就可以直接获得目标文档,不必再在不同的系统间来回跳转,而是用一种全新的方式把沉淀的知识循环起来。
参照一百多年前的“福特式流水线”,在人工智能催生的新一轮工业革命中,知识管理也将更加“流水线化”,以往躺在“故纸堆”和系统里的广义知识被大模型加速循环,或许就是知识管理质变的开始。
04 写在最后
回顾整个2023 WAVE SUMMIT,除了如流对办公场景的重构,“文心一言”的5大原生插件,让大语言模型的能力边界进一步扩展;飞桨开源框架迎来2.5版本,围绕大模型的训练、推理、硬件适配进行了全面升级;星河大模型社区、大模型插件机制以及生态计划,不断降低大模型落地应用的门槛。
据百度披露数据,目前飞桨已经凝聚800万开发者,服务20万家企事业单位,基于飞桨创建了80万个模型。大模型重构的将不仅仅是办公场景,这只是一个缩影,越来越多的场景即将或正在被大模型重构。
