
夕小瑶科技说 分享
Lucy,是距今320万年最早的人类祖先,也是被输入某种“物质”后大脑开发到100%的超智能人类,能感知宇宙万物,拥有人类所有知识。如果大模型是Lucy,那么LucyEval即是助力其更智能的奇妙”物质“。
随着大语言模型不断调优,大模型拥有了更优越的理解人类话语、指令并且生成类似人类语言文本的能力。机器和人类终归不同,如何最快速地判断机器是否能正确理解人类的知识和语言,成为我们共同关注的问题。
由此,甲骨易AI研究院推出了中文大语言模型成熟度评测——LucyEval,能够通过对模型各方面能力的客观测试,找到模型的不足,帮助设计者和工程师更加精准地调整、训练模型,助力大模型不断迈向更智能的未来。

Lucy的每一个字母背后都代表了不同的意义,包含着甲骨易AI研究院设计LucyEval时所考量的维度和坚持的理念。
L - Linguistic Fundamentals: 基础理解能力
U - Utilization of Knowledge: 知识运用能力
C - Cognitive Reasoning: 推理能力
Y - Yield of Specialized Outputs: 特殊生成能力
"Lucy" 包含以下含义:
Linguistic Fundamentals (基础理解能力) :描述模型对基础语法、词汇和句子结构的理解程度。
Utilization of Knowledge (知识运用能力):衡量模型在回答问题或生成文本时如何运用其内嵌的知识。
Cognitive Reasoning (推理能力):评价模型是否能从给定的信息中进行逻辑推断或解决复杂问题。
Yield of Specialized Outputs (特殊生成能力):测试模型在生成特定类型或风格的文本(例如诗歌、代码或专业文章)时的效能。
目前,LucyEval已发布如下两项测试集。
大规模多任务中文理解能力测试 Massive Multitask Chinese Understanding
2023年4月25日,针对中文大模型理解能力测试缺失且推出高质量中文评测数据集迫在眉睫这一现状,甲骨易AI研究院率先发布(首发)了一套大规模多任务中文大模型理解能力测试。
测试所包含的题目来自医疗、法律、心理学和教育四个科目的11900个问题,包含单项选择和多项选择题,目的旨在使测试过程中模型更接近人类考试的方式,覆盖学科面广,专业知识难度高,适合用来评估大模型的综合理解能力。
论文链接:
https://arxiv.org/abs/2304.12986
中文大模型多学科生成能力自动化评测基准 Chinese Generation Evaluation
目前领域内的评测大多都只针对模型的中文理解能力,通过选择题由模型直接生成答案,或者提取模型对各个答案选项的输出概率。从评测大模型的生成能力的角度,这些评测基准就存在很大的局限性。
在率先发布国内首个中文大模型理解能力测试后,甲骨易AI研究院于8月9日正式发布一套自动测评中文大模型多学科生成能力的评测基准。
基准包含11000道题目,涵盖科技工程、人文与社会科学、数学计算、医师资格考试、司法考试、注册会计师考试等科目下的55个子科目。题型分为名词解释、简答题和计算题三种类型。同时,甲骨易AI研究院还设计了一套复合打分方式Gscore,使评分过程更加合理、科学。
甲骨易AI研究院使用本评测基准对以下模型进行了zero-shot测试,包括GPT-4、ChatGLM-Std、讯飞星火Spark Desk、文心一言ERNIE Bot等。
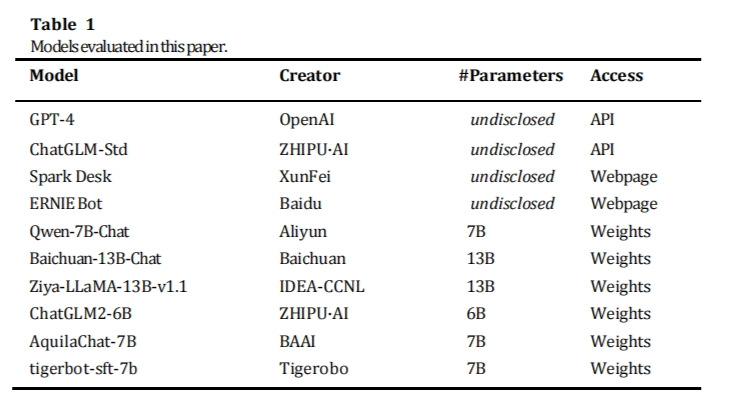
本次受测中文大语言模型
从所有模型在六大类科目的平均分来看,GPT-4取得最高分41.12,比最低分32.28高出8.84分。

本次受测中文大语言模型平均得分
受测模型在其他学科的表现详见评测地址:
http://lucyeval.besteasy.com/
未来,甲骨易AI研究院将矢志不移地为提升中文大语言模型能力为目标,持续研究适应其发展的测试集,期待与同样关注大语言模型发展的业界同仁携手共建。
论文链接:
https://arxiv.org/abs/2308.04823
更多AI相关资讯,请关注微信公众号:甲骨易
