
在这一轮AI浪潮中,“技术为先”和“产业为先”的争论一直存在:前者以通用人工智能为终极目标,追求构建更大、更强、更通用的模型;后者认为AI的价值在于解决实际问题,技术是为场景服务的工具。
“技术为先”与“产业为先”并非绝对对立,更像是螺旋式上升的关系:技术拓展应用边界,产业校准创新方向。
中国拥有全球唯一的全工业门类、全球最大规模的金融消费人群以及最大规模的政务和城市体系,产生了丰富的场景和私有数据,大模型又恰恰遵循着“吃什么行业的数据,就更懂什么行业的知识”的逻辑。
所以,不同于欧美对“技术为先”的推崇,最适合中国企业的是“产业为先”的差异化路线。
01 中国的产业土壤,为AI提供了天然试炼场
人工智能的发展路径,从来都不是单一技术逻辑的自然延伸,而是结合战略定位、产业结构与资源禀赋的系统性选择。之所以不应照搬欧美的“技术为先”模式,在于国内有两个特殊的产业背景。
第一个是产业“全、多、广、深”,为AI训练和部署提供了最真实的环境。
比如在工业领域,国内拥有联合国产业分类中的全部工业门类,500多个工业品种中,中国有四成以上的产量位居全球第一。只有经历过足够复杂、足够真实、足够有价值的场景淬炼,AI才能走出实验室走向生产一线。
比如在金融行业,银行、保险、证券等机构拥有全国最全、最及时的个人与企业交易数据,在风控、反欺诈、投资组合、客户画像等方面,对模型的准确性、响应速度、安全性要求极高,是锤炼工程能力的天然试验场。
再比如政府数字化改革不断深入,交通、医保、社保、应急、教育等业务系统加速智能化,高复杂度的公共治理场景,对大模型的泛化能力、决策准确性、安全性提出了严苛要求,是AI走向“可用、可管、可信”的关键落点。
第二个是海量数据的天然优势,构成了AI落地不可替代的基础资源。
作为全球数字化发展最活跃的国家之一,中国长期积累了海量、多源、高价值的数据资源,形成了独特的“数据沃土”。
一方面,中国拥有全球最大规模的互联网用户群体、活跃的数字经济生态与高速发展的信息基础设施,带来了庞大而持续增长的非结构化数据资源。相关统计数据显示,2023年中国的数据产量约占全球数据总产量的23%,位居世界第一,预计2025年中国数据总产量将达48.6ZB,约占全球的1/3。
另一方面,政府、金融、央国企等关键主体,掌握着覆盖国计民生、国民经济核心领域的大量结构化数据,是训练和精调大模型的“优质燃料”。其中长期深耕于能源、通信、交通、建筑等重点行业的央国企,沉淀了大量结构化、专业化、高价值的数据资产,拥有AI向产业纵深发展的先天优势。

正因如此,在产业链中有着资源统筹能力的政企单位,可以说天生就是AI落地的“产业链组织者”和“生态统筹者”,在打通数据要素流通、推动AI工程化落地方面有着不可或缺的作用。
早在"十四五"规划中,就已经对政企提出明确要求:"加快推动数字产业化、产业数字化",并首次将"数据要素市场化"纳入国家战略。
国资委两次召开央企"AI+"专项行动会,强调推动国资央企在人工智能领域实现更好发展、发挥更大作用,推动一批高价值行业应用场景落地,稳步推进数据集建设,大模型构建加速追赶。
根植中国工业体系的央国企、走在转型前线的金融和政府机构,被推向了数智化转型的第一线,既是推动者,也是试验田,正在担纲起引路者、落地者与示范者的三重角色。
02 从行业先行者实践中,透视AI应用落地的关键锚点
根据德勤的研究数据,已经有超过70%的央企、超过55%的地方国企启动了数智化转型工作,成立了近500家数字科技类公司。
如果说通往AGI的挑战主要集中在训练方法、推理优化、对齐技术、新的学习范式等底层研究上,AI在产业落地则是更加复杂的系统性工程。在行业头部先行者探索AI大模型应用落地的过程中,可以看到四个共性的需求。
一是对安全可控、长期稳定、可靠的基本诉求。
政府和金融机构、大型央国企通常承担履行国家战略安全、引领产业、支撑国计民生、提供公共服务等责任,数据安全和业务稳定运行至关重要。
迈向智能时代,大模型的训练和推理通常需要海量算力支撑。以金融行业为例,据公开信息显示,工行、邮储、招商银行等金融头部机构,为了满足万亿参数大模型的高并发推理需求,纷纷部署了千卡云算力集群。
如何解决超大规模算力集群的弹性调度、长稳运行以及异构资源的统一管理等问题,也成为政企所面临的挑战。特别是在 DeepSeek 发布后,能否在集群上快速部署并上线,也成了摆在案头的考验。
在某大型国有银行,应用了华为云Stack混合云之后,基于云平台的动态调度,统一管理等能力,实现了算力资源实时监控、动态扩缩容、朝推夜训等功能,算力利用率提升了30%,千卡集群稳定运行时长提高到了40天,故障恢复缩短到了分钟级。
DeepSeek的能力和价值被市场验证后,这家国有银行依托算力云的快速部署能力,仅用2天时间,就在千卡集群上部署106个DeepSeek实例,日调用量超过15万人次。
二是解决数据治理和流通难题,为大模型高质量供数。
在过去十多年数字化进程中,央企积累了大量的行业数据,通过对这些数据的整合、清洗和共享,能够为人工智能模型的训练提供高质量的数据支持,提升模型的性能和准确性。央企还可以牵头建立数据标准和规范,促进数据的流通和共享,推动数据要素市场的健康发展。
同时也要看到,大型央国企多半是集团型企业,多层级、多产业,而且资产在境内外均有分布。由于发展过程中历经多次重组合并,形成了各业务单元“各自为战”的局面,导致集团整体的结构性与连接性不足。
在数据治理方面,横向上尚未全面拉通端到端流程,不利于统筹各事业部、各区域、各职能形成合力,实现围绕客户需求的高效响应和交付;纵向上缺乏组织、流程和数据抓手推进数据治理落地,不利于自上而下落实数据管理规范,且难以深挖数据背后的风险与价值。
徐工集团携手华为打造了强大的大数据平台和混合云底座,构建数据治理体系,持续将数据统一入湖。在车联网设备360画像场景中,徐工集团通过将各类工程机械车辆的运行数据汇聚到大数据平台进行价值挖掘,为客户提供“管用养换”增值服务。
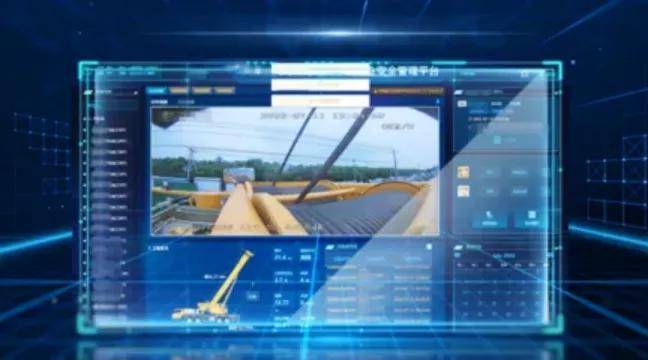
有了高质量数据集,徐工集团还搭建AI大模型及收集和标注训练数据集,以智能问答、自动驾驶的视觉感知、产品作业的自动化施工等场景为切入点,让AI在企业运营过程中可观可感。
三是大模型如何从“更聪明”到“更懂行”。
虽然通用大模型在自然语言处理方面展现出了卓越的能力,但在特定行业理解中仍然存在一定的局限性,难以准确把握复杂的行业规范和流程,导致结果有偏差。这就需要利用工具和平台对通用大模型进行二次训练和调优。
现实世界问题总是复杂多样的,尤其是通常央国企的业务领域覆盖产业链上下游核心环节,加上工业制造的生产场景多且复杂,单一的AI模型无法满足所有场景的需求。
以一家典型的制造企业为例,既有销服环节的智能问答、知识库场景,也有生产环节的工厂入侵、异常事件预警、生产工艺优化等场景,需要自然语言模型、机器视觉模型、预测模型等多个模型协同运行,怎么调用不同模型最擅长的能力、怎么提高多模型并存的推理效率……无不是必须要攻克的技术瓶颈。
湘钢依托携手华为等伙伴发布了全球首个钢铁行业人工智能大模型并在三十多个场景落地。通过建设统一云基础设施、大模型一站式开发平台,湘钢建立起“中心训练、边缘推理、云边协同、边用边学、持续优化”的机制,将模型开发从传统的作坊式生产转向现代工业化流水线生产,将专家经验知识和模型开发过程以工作流的方式沉淀在大模型平台上,快速复制推广到生产过程中,同时还可培养企业自己的智能化队伍。

四是AI应用的研发效率跟不上需求。
建设算力中心、开展数据治理、训练行业模型等只是过程,结果是要让AI的能力通过实际业务应用系统来得到应用,最终有效地提高生产效率、降低制造成本、提高质量和管理水平,形成投入和产出的正向循环。在AI时代下,所有应用都值得再做一遍。
现实中存在的问题在于,政企由于软件开发能力相对较弱,无法有效地度量软件的进度、生产率和质量,项目管理无法可视化,同时可能面临上百家乃至更多供应商,如何协同企业内部的各业务组织和供应商,找到高效的应用开发和协作范式,已然成为央国企在应用开发上的主要难题。
作为知名的海上油气生产运营商,中国海洋石油集团有限公司在代码的研发过程中,由于缺乏统一的管理工具、规范和标准,功能、产品迭代的效率不高,中海油3000多软件开发人员都受到影响。中海油主动求变,内部成立专项软件工具链科研项目,积极探索开发智能化应用,寻找更有效率的研发方案。

中海油引入了华为云Stack提供的软件开发生产线CodeArts后,中海油已经开发了智能采办、智能油田二期、应用开发云平台等主要业务系统,构建了中海油供应链一体化数字化平台。研发工时节省了30%,智能油田管理系统集成、调试、部署时间从1周缩短为1天。
上述共性问题的出现,折射了AI应用落地的多元挑战,更揭示了一个共识,在AI时代的浪潮中,唯有通过云计算找到技术锚点,才能建立可持续的竞争壁垒从而驾驭创新。一朵同时具备高韧性和安全合规,可支撑数据+AI+应用开发的,具备丰富行业实践的混合云技术底座,更能满足政企数智化的发展需求。
03 从经验到解决方案,“产业为先”的路跑通了
从上述实例中不难看到,央国企直面AI落地挑战的过程中,少不了懂技术、懂行业的“同行者”,其中就包括深耕政企市场十数年的华为。
早在2008年的时候,华为就开始投入到云计算相关技术的研发,面向政企市场构建稳定、安全、具备韧性的云平台。在数据基础设施领域,围绕数据湖、数据工程、数据空间可信交换等关键技术方向不断深化布局,为大模型训练与应用提供高质量的数据支撑;在人工智能领域,逐步完善了从基础设施到AI平台、再到行业方案的能力体系,持续增强面向政企场景的AI产品与方案竞争力;同时将自身的IPD流程、工具和经验,都沉淀到软件开发生产线,帮助政企客户加快应用现代化进程。
通过在政企数智化关键能力领域的不断持续投入,再加上长期浸沁政企市场,对政企业务和发展诉求理解深刻,华为云Stack逐步形成“智能时代更懂政企”的云服务能力体系。
在华为开发者大会2025上,华为混合云总裁肖霏提出,在智能时代,理解用户、为细分用户群提供具体的软件与AI能力显得尤为重要。他认为,主要有四类典型政企用户:数据中心工程师、数据工程师、AI算法模型应用工程师、应用开发工程师。围绕这四类政企用户群体,华为云Stack从“建云、上云、用云、管云”全业务流程视角,构建并持续强化从云平台到数智融合,再到各类生产工具链等产品和方案,使能政企用户调度好资源、治理好数据,训练好模型,开发好应用。
会上,肖霏还正式宣布,华为云Stack将在下半年率先全面适配CloudMatrix 384超节点。这也是业界首个支持超节点的混合云,届时,政企客户将在本地也能建设和公有云一样的超节点算力。
 图:华为混合云总裁肖霏
图:华为混合云总裁肖霏
针对数智化转型中的机遇和挑战,华为云和大型政企客户验证了一条可行的路,那就是政企担纲头雁领航,以云+AI为核心,充分发挥海量数据和丰富场景优势,通过应用领航、数据赋能和智算筑基,重塑全行业的竞争力,抢占未来产业发展的制高点。
在数智化转型的过程中,并非所有企业都有试错的资本,有场景、有数据、有产业话语权的大型政企,正在和华为云等代表同行者一起,解难题、做难事,打通AI落地应用的通路。
