1月26日,天数智芯在上海开了一场发布会。
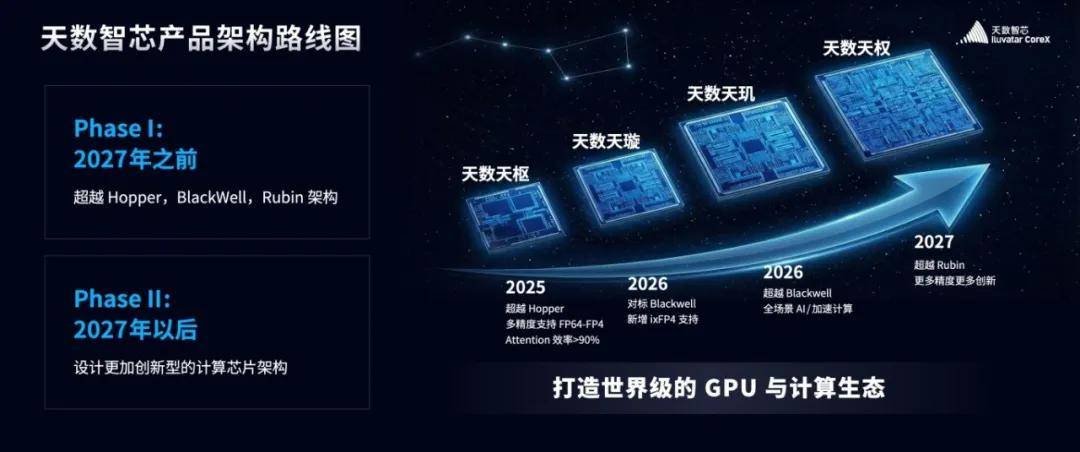
说实话,如果只是"又一家国产芯片公司发新品",我不会特别关注。但这次有点不一样——他们直接把"超越英伟达"的时间点发布出来了:2025年超越英伟达Hopper架构(实测已超越20%),2026年对标Blackwell架构,2027年超越目前英伟达最先进的Rubin架构。国产芯片公司公开叫板英伟达,这种事你听得多了。但把具体年份、实测性能写清楚的,不多见。
要么是真有底气,要么是不怕打脸。
我研究了一下他们的材料,发现这事可能比想象中有意思。
1
路线图第一步,已经验证了
很多人一听"超越英伟达"就觉得怎么可能?毕竟这样的故事被讲的比较多了。但这次有个细节值得注意:路线图的第一步,2025年推出的天数天枢架构,在当前备受瞩目的DeepSeek V3场景下,其性能较英伟达Hopper提升了约20%,成为首个实现对国际主流架构实质性超越的国产方案。
这不是实验室跑分,是在真实业务场景下的推理性能。
另一个数据更有意思。AI芯片在执行注意力机制(Attention)等关键计算时,天枢架构的算力有效率达到90%以上,比行业平均水平高出60%。
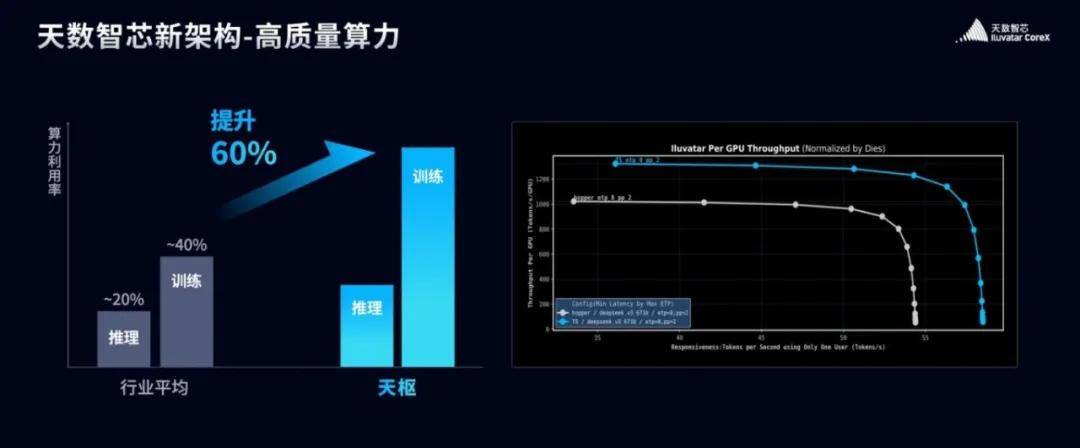
这不是堆参数换来的性能提升,是从底层架构就开始的优化。
具体怎么做的?他们公开了三个技术细节:
TPC BroadCast(广播机制)设计通过上游数据广播减少重复访存,等效提升带宽并降低功耗。
Instruction Co-Exec(多指令并行处理系统)设计实现多类型指令并行处理,增强复杂任务处理能力。
Dynamic Warp Scheduling(动态线程组调度系统)机制则通过动态调度避免资源争抢,提升计算资源利用率。
听起来很技术?简单说就是:别人家芯片算完一步等下一步,天数智芯的芯片能同时干好几件事,还能自己调度,不让资源闲着。
这套东西的效果,被很多客户验证过了。
阶跃星辰用天数智芯的芯片做文生图、文生视频,定制了int8量化算法,性能提升80%。IX-QUANT模块做计算量化并行处理,又提升50%。头部互联网客户用多任务并行处理系统,提升30%;长上下文IX-Attention模块,提升20%。
这些数字来自实际部署,不是benchmark跑分。
2
边端产品:另一个战场
除了云端GPU,天数智芯这次还发布了边端产品线"彤央"系列。

四款产品,定位不同:
- 彤央 TY1000:采用 699pin 接口,以口袋大小集成行业级算力与开放生态,实现便携化部署;
- 彤央 TY1100:集成ARM v9 12核CPU 与自研GPU模组,以充沛算力提供多元选择;
- 彤央TY1100_NX:更大显存,堪称边端算力“小钢炮”;
- 彤央TY1200:300TOPs 的极致性能,为 AIPC、具身智能等前沿场景提供核心支撑。
关键数据:彤央全系列的本地算力覆盖100T到300T范围,并且是“稠密算力”(面向数据密集型、高并行度计算场景的高效计算)。
在计算机视觉、自然语言处理、DeepSeek 32B 大语言模型、具身智能VLA模型及世界模型等多个场景的实测中,彤央TY1000的性能全面优于英伟达AGX Orin。你看,从云端到边端,从大模型训练到推理部署,天数智芯在按产品线全面铺开。这不是单点突破,是全线进攻的战略。
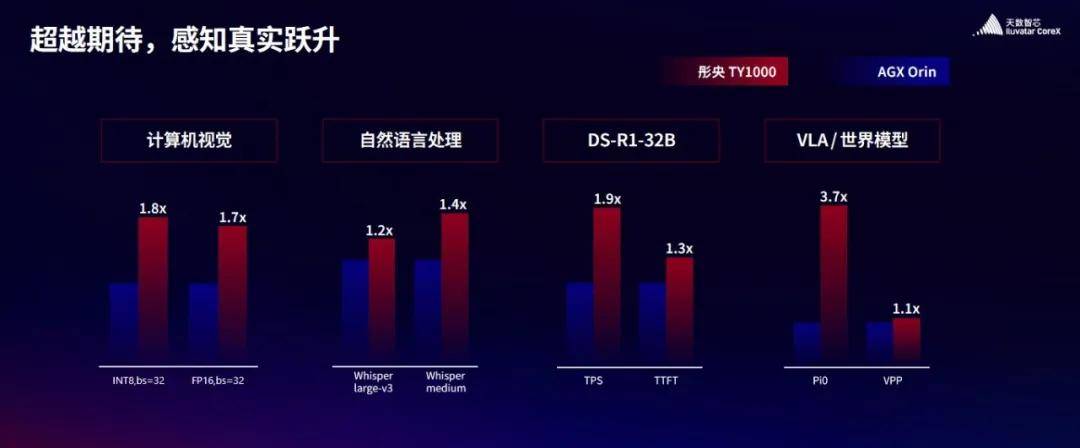
边端这块市场,英伟达Orin系列一直是标杆。国产芯片能在实测中超越Orin,意味着智能驾驶、机器人、智能工业等这些场景,有了真正可用的国产替代方案。
3
300家客户、1000次部署,这组数字说明什么
天数智芯这次首次公开了客户和部署数据:
300+客户,1000+次部署实战,数千卡集群稳定运行超1000天。
涵盖互联网、大模型、科研、金融、医疗、交通等领域。

举几个例子:
在互联网AI领域,天数智芯实现了单机性能翻倍、Token成本减半、人力节省1/3;在大模型适配上,达成95%算子复用。
在科学探索领域,适配320种通用计算模型,单集群可并行数千卡科研任务,稳定运行1000多天,已落地国内多家顶级学府。
金融领域,研报生成效率提升70%,量化分析响应速度提升30%。
医疗领域,结构化病历生成时间缩至 30 秒/份,肠胃镜病灶定位精度提升30%。
1000天这个数字要单独说一下。
几千卡规模的算力集群,稳定运行超过1000天,这背后考验的不只是芯片硬件的可靠性,还有系统稳定性、软件支持体系、运维响应能力的综合实力。这不是PPT能画出来的,只能靠时间来验证。
4
为什么是"高质量算力"
天数智芯这次反复提一个概念:高质量算力。
什么意思?他们给了三个维度的定义:
高效率:不是比谁参数大,而是比谁把算力真正用起来。理论峰值再高,实际利用率只有20%,等于浪费80%的钱。
可预期:建设算力中心、搭建算力集群都是大工程。他们有个业界独家的IX-SIMU全栈软件仿真系统,可以在部署前预测性能表现。部署前就能通过仿真系统模拟实际运行效果,减少"上线后发现不行"的风险。
可持续:不只是跑今天的算法,还要能跑未来的算法。从CNN到RNN到Transformer,再到未来的模型架构,芯片要能持续适配。
这个思路很有意思。
过去几年,整个行业都在追求"更大的TFLOPS"。但大家逐渐发现,理论峰值和实际效果之间有巨大的鸿沟。买回来一堆算力,实际能用的可能不到一半。剩下的要么在等数据,要么在等调度,要么被各种系统开销吃掉了。天数智芯的策略是:与其卷参数,不如卷效率。把同样的硬件条件下,能用起来的算力比例提上去。
从商业角度看,这意味着客户的TCO(总拥有成本)更低。花同样的钱,能干更多的活。这比单纯的"便宜"更有吸引力。便宜如果不好用,是浪费。便宜又好用,才是真省钱。
5
这场仗怎么看
国产GPU的竞争格局,正在从"能不能用"转向"好不好用"。
第一阶段是解决有无问题:能不能做出来、能不能跑起来。这个阶段已经过去了。
第二阶段是解决可用性问题:性能、稳定性、生态、成本,综合起来能不能在真实业务场景中替代进口方案。
天数智芯这次发布的内容,核心在于证明一件事:他们已经从"实验室可用"进入到"规模化落地"阶段。
芯片这个行业,从来不是嘴炮能赢的。最终决定胜负的,是客户愿不愿意把业务放上来跑,跑完之后愿不愿意继续用。
芯片竞争,从来不是比谁的PPT更好看。
是比谁能在真实场景中,解决真实问题,创造真实价值。
天数智芯已经展示了自己的答卷。
